Vision Transformers (ViTs), with their ability to model long-range dependencies through self-attention mechanisms, have become a standard architecture in computer vision. However, the interpretability of these models remains a challenge. To address this, we propose LeGrad, an explainability method specifically designed for ViTs.
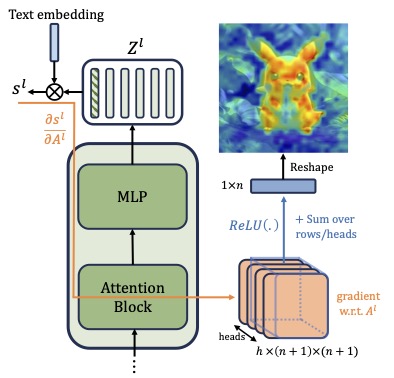
LeGrad computes the gradient with respect to the attention maps of ViT layers, considering the gradient itself as the explainability signal. We aggregate the signal over all layers, combining the activations of the last as well as intermediate tokens to produce the merged explainability map. This makes LeGrad a conceptually simple and an easy-to-implement tool for enhancing the transparency of ViTs.
We evaluate LeGrad in challenging segmentation, perturbation, and open-vocabulary settings, showcasing its versatility compared to other SotA explainability methods demonstrating its superior spatial fidelity and robustness to perturbations.
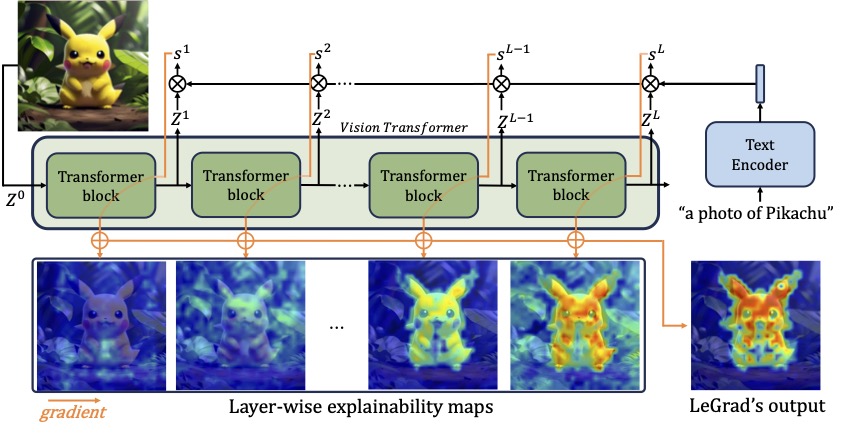
LeGrad introduces a novel explainability approach for Vision Transformers (ViTs) by elucidating the sensitivity of feature formation across different layers of the model. By focusing on the model's attention mechanism, LeGrad computes gradients to highlight image regions pivotal for the model's decision-making process. This method not only provides insights for a single layer but also aggregates information across multiple layers to offer a comprehensive understanding of how each image region contributes to the final prediction. Through this technique, LeGrad aims to enhance the interpretability of ViTs, offering a clearer perspective on the model's internal workings and decision rationale.
Impact of each layer on the merged perdition, using "a photo of a cat" as prompt for the last layers of ViT-H/14.

Image

Merged Prediction

pip install legrad_torch
@article{bousselham2024legrad,
author = {Bousselham, Walid and Boggust, Angie and Chaybouti, Sofian and Strobelt, Hendrik and Kuehne, Hilde}
title = {LeGrad: An Explainability Method for Vision Transformers via Feature Formation Sensitivity},
journal = {arXiv preprint arXiv:2404.03214},
year = {2024},
}